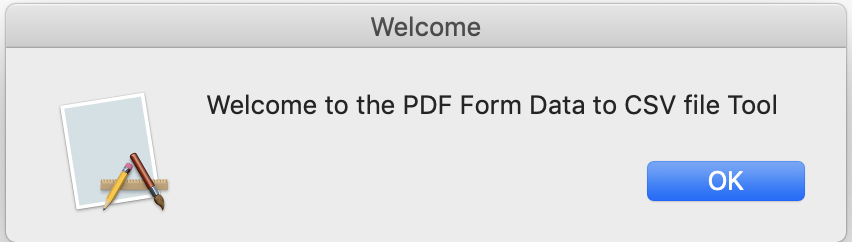
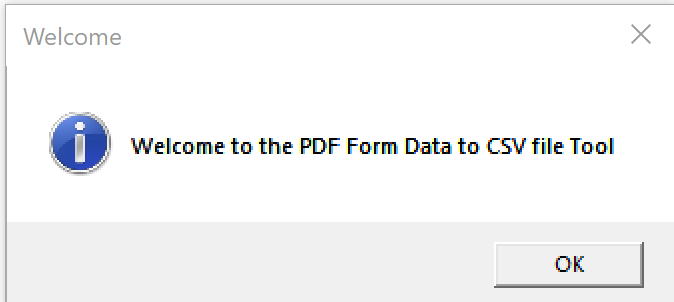
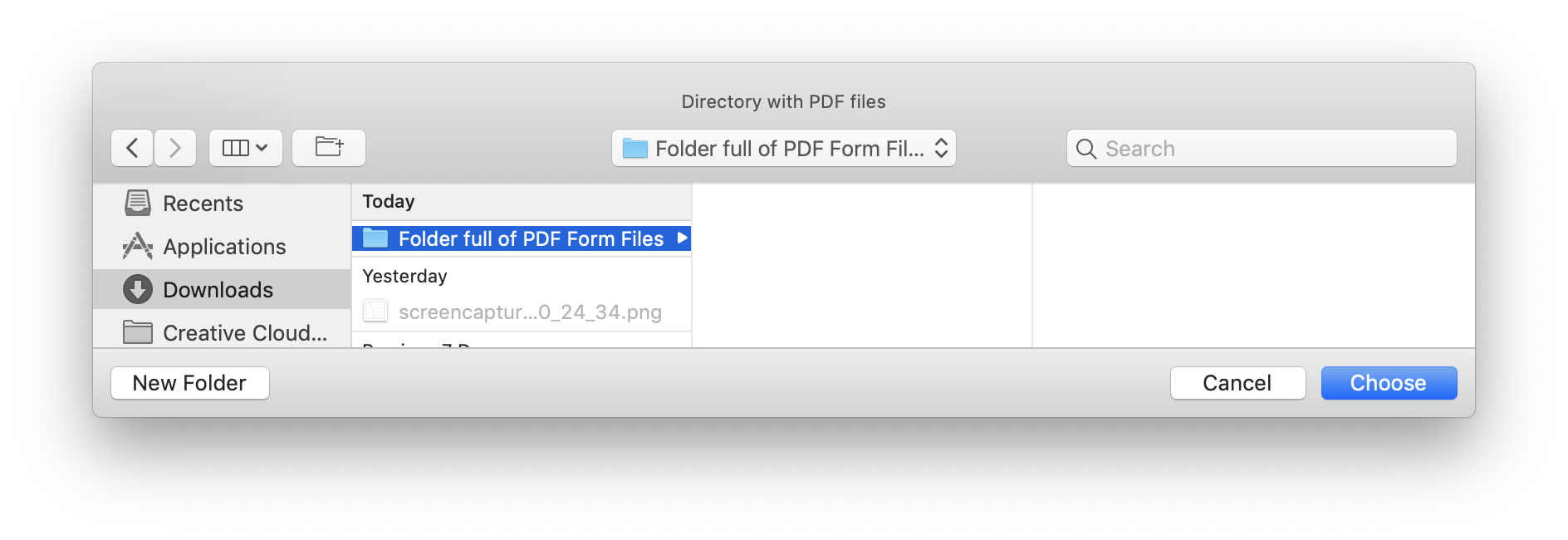
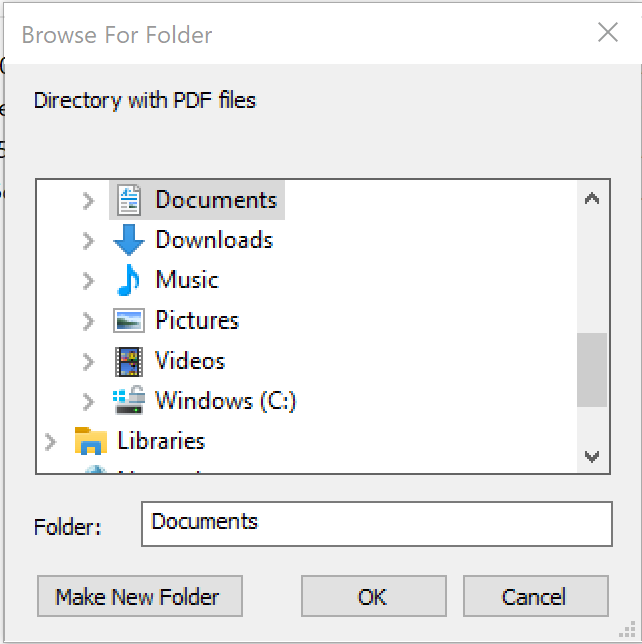
Extracting Data from PDF Forms into CSV Files PDF to Excel with a GUI! On Windows or MacOS!
My friend has a cool job helping people stay out of jail in Washtenaw County, Michigan, USA. That lofty mission, like so many these days, is underpinned by the lowly PDF form. I wanted to make her job easier by automating the extraction of data from those forms into a summary spreadsheet.
tl;dr: Everyone on the Internet is cool and lets you use their code
and you can put it all together to do other cool things. This is no
exception, so big thanks to: Milan Nikolic for the very nice dlgs
dialog box code; the PDF CPU project for the PDF parsing code; and
Simon Eskildsen for his very friendly logrus logging code.
The first problem: Parsing PDF Form Data
The PDF CPU library does a very nice job of returning a map of form
element labels and the data that was entered into the form. This is
done in the parsePdfForm routine.
One of the downsides of this approach is that the form element labels as generated by Acrobat’s conversion of input files (like Word files) to PDF forms are, by default, randomly grabbed from the surrounding context, so sometimes are not useful and can seemingly be up to 99 characters long. I use these as the CSV column headings, so they can be sort of confusing and very annoying. I couldn’t think of a better way to do this in the general case, so this is what you get. I did consider supporting a file that maps between what’s in the form and what you want as headings, or a GUI that let’s you rename the fields before writing the summary, but that seemed like a lot of extra work for version 1.0.0, so skipped it.
The second problem: Not all of the PDF files are the same
It is possible that the PDF forms will change over time with added fields, changed fields, removed fields, or just be altogether different forms. After parsing all of the PDF files in the target directory, we have a set of form fields (the result of the “first problem”). What do we write as the summary? Does the first file read define the set of fields? Is the set the intersection of them, so only those fields that appear in all of the forms also appear in the summary? Is it the union of them, so every field that appears in any form appears in the summary? Is there some other configuration read from a file or developed interactively via a GUI that is used to define the fields in the summary?
The easiest thing is to keep the union of all of the fields. This can lead to weird output, though, and also requires that all of the files are read and processed before the summary can begin to be created. For example, say you have two PDF Form files, one is to order a hamburger and one is to order a book. You could end up with a summary file that looks like:
| File | Number of Patties | Wheat Bun | Title | Author |
|---|---|---|---|---|
| book.pdf | The TeX Book | D. Knuth | ||
| hburg.pdf | 2 | On | ||
| zbook.pdf | CDB! | W. Steig |
In order to make the headings, the program has to know all of the
form fields from all of the forms, then it has to go through each
set of data from each form and and fill in the table, not
compressing the data upwards, but keeping it aligned with the file
from which it came. Annoying and error-prone, at least the way I
first did it. This is done in the function structData.
The third problem: Icons
No problem: The results
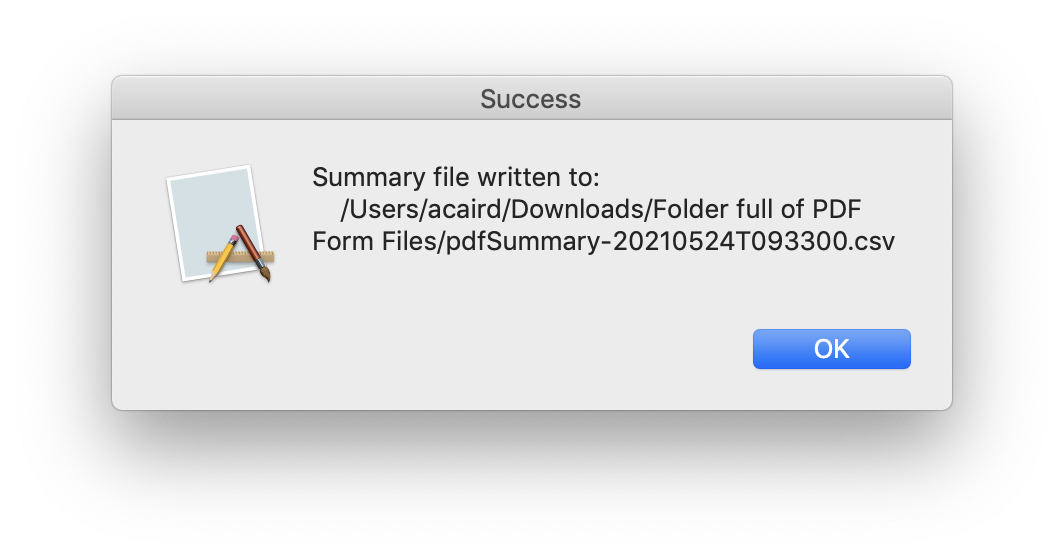
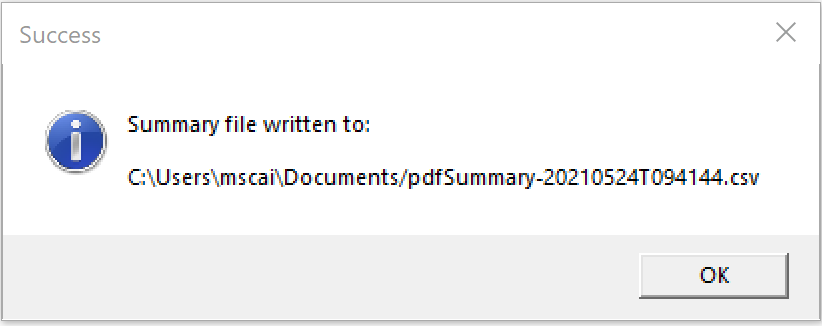
In a Go program of just over 300 lines and some extra support files, I have a cross-platform, single file (well, sort of, for the Mac) application that has a graphical interface to reading a directory full of PDF Form files and writes to that same directory a CSV file summarizing the data from the PDF files: https://github.com/acaird/pdfform2csv
| MacOS | Windows |
 |
 |
 |
 |
 |
 |